Conception et réalisation d’un phonologiseur automatique du français
Basilio Calderone
Background
Nos travaux sur la phonologisation automatique s’inscrivent dans un programme d’amélioration et d’enrichissement des ressources lexicales existantes pour la langue française. En particulier, la création de lexiques contenant des informations phonologiques, bien qu’essentielle pour la recherche en linguistique, apparaît souvent déficiente et de faible couverture. L’idée développée et mise en œuvre dans le cadre du programme Demonext était de combiner et d’optimiser les fonctionnalités de deux lexiques français existants : Flexique et GLÀFF.
Flexique et GLÀFF
Flexique est un lexique flexionnel phonétisé du français standard, distribué sous licence libre.
Il se caractérise par la qualité de ses transcriptions phonologiques et par certains choix de méthode. Par exemple, pour les formes ayant de multiples réalisations phonologiques régulières, un arbitrage a été effectué, de manière à avoir une transcription unique aussi proche que possible de la forme de surface, mais à partir de laquelle les autres réalisations possibles peuvent être déduites. Excepté en position finale de mot, les schwas ont été inclus systématiquement, même dans les cas où la réalisation effective d’un schwa est très peu fréquente. Dans sa forme actuelle, cette ressource comporte trois tables correspondant respectivement aux noms, adjectifs et verbes du français, pour un total de près de 50 000 lexèmes et plus de 350 000 formes fléchies.
GLÀFF, est un lexique à large couverture construit à partir du Wiktionnaire, comprend 1,4 millions d’entrées (180 000 lexèmes) et fournit pour chacune d’elle un lemme, une description morphosyntaxique et, dans 90% des cas, une ou plusieurs transcriptions phonémiques.
Les transcriptions phonologiques de GLÀFF ne sont pas normalisées et manquent de cohérence, car elles sont le résultat de l’intuition « naïve » des contributeurs.
L’idée directrice du présent travail est d’utiliser la qualité des transcriptions phonologiques de Flexique afin de réaliser une phonologisation automatique normalisée et « de qualité » pour toutes les entrées de GLÀFF.
Le modèle
Sur le plan méthodologique, nous avons utilisé un algorithme d’apprentissage automatique LSTM (Long Short-Term Memory), capables de traiter des séquences de symboles en entrée et en sortie.
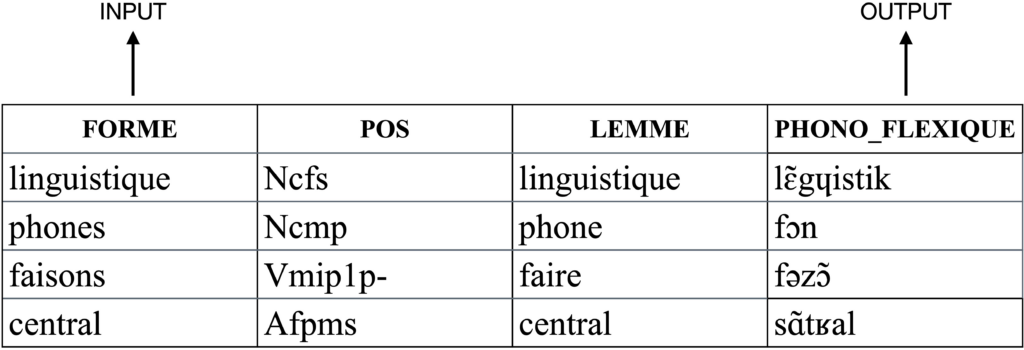
Plus précisément, notre phonologiseur automatique est capable de recevoir en entrée une forme orthographique et de prédire sa transcription phonologique en sortie, voir le Tableau 1.
Pour l’entraînement, nous avons utilisé un jeu de données composé de l’intersection GLÀFF et de Flexique calculée sur les formes orthographiques (actuellement, seuls les noms, les verbes et les adjectifs composent notre jeu de données. Les adverbes et les autres catégories sont exclus). Le data training contient 330 000 formes créées en associant à chaque forme orthographique (la même dans GLÀFF et Flexique) sa transcription phonologique dans Flexique.
Les résultats
La prédiction de la transcription phonologique sur un jeu de test de 30 000 formes (10% du dataset) composé de données qui ne sont pas présentes dans le jeu d’apprentissage, a montrée une exactitude de 97,77%.
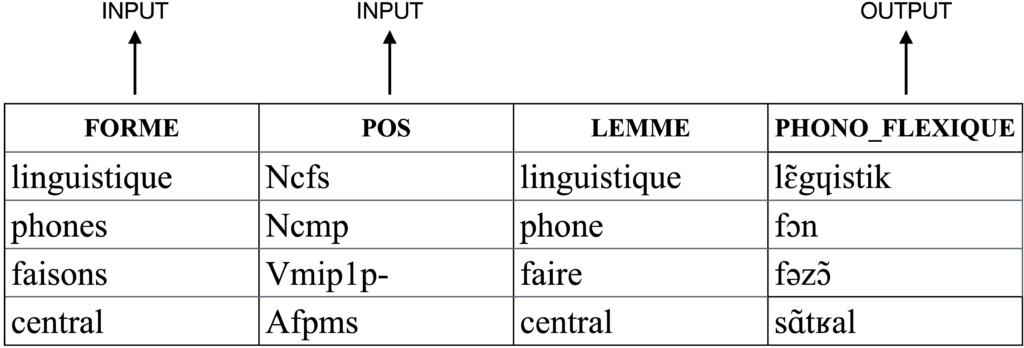
Un second modèle (modèle 2, voir Tableau 2) a également été construit. Cette nouvelle architecture prend en entrée la forme orthographique et la catégorie grammaticale avec ses attributs morphosyntaxiques, techniquement représentées par une variable catégorielle. Le modèle 2 obtient une exactitude de 98,91% sur les 30 000 formes du jeu d’évaluation (i.e. du jeu de test).
Un aspect à explorer plus avant est la capacité du système à associer un score de probabilité {0,1} pour chaque phonème qui constitue la transcription phonologique de sortie. Les transcriptions incorrectes ou improbables auront une probabilité plus faible que les transcriptions phonologiques plus facilement prévisibles et systématiques. Cela peut permettre la détection automatique des parties phonotactiques (ou bien mots entiers) susceptibles de comporter une erreur.